

Photo by Cris Ovalle on Unsplash
After several months working on a final approach to accomplish this task, I finally found one to do this in an efficient and fast way.
But, first, let me start with the requirements we got from one of our companies at Intercorp.
We are heavy users of Google Cloud Platform here, so as a Data Engineer; I have the pleasure to work with several of these companies to move their data to Google Cloud entirely.
So the requirements we got for this particular solution were the following ones:
- The data will arrive to a Google Cloud Storage bucket daily
- We have to apply some transformations to this data and then upload to their corresponding tables in BigQuery
In order to accomplish this task, we are using several services at the same time:
- Google Cloud Storage for daily records storage
- BigQuery for data analytics
- Cloud Run for a service API to get the last file in the bucket folder of Google Cloud Storage
- Matillion for BigQuery for the data transformation
I will divide this post in two parts:
- Part I: Cloud Run API to get the last file of Google Cloud Storage bucket
- Part II: Moving the data from Google Cloud Storage to BigQuery with their respective transformations
Part I: Cloud Run API to get the last file of Google Cloud Storage bucket
But you should be wondering why I’m talking about Cloud Run here. Let 's dive into why.
If you don’t know what Cloud Run is, I will give you a quick overview here:
It’s a platform to deploy entire applications on top of containers in a serverless faction.
The official description of the service by the Google Cloud team is the following:
Cloud Run is a managed compute platform that enables you to run stateless containers that are invocable via web requests or Pub/Sub events. Cloud Run is serverless: it abstracts away all infrastructure management, so you can focus on what matters most — building great applications.
I have to say it: Cloud Run is one of my favorite services from the entire Google Cloud ecosystem, and I use it almost daily to build fast REST-based APIs on top of Python, Flask and Firestore.
But, let’s stop the chat-chat and let’s dive in the code.
In order to deploy a Cloud Run application on Google Cloud, first, you need a Google Cloud account, a Google Cloud project, Python and the Google Cloud SDK.
Let’s start with the Google Cloud SDK:
- Download the SDK from this link and install it in your computer
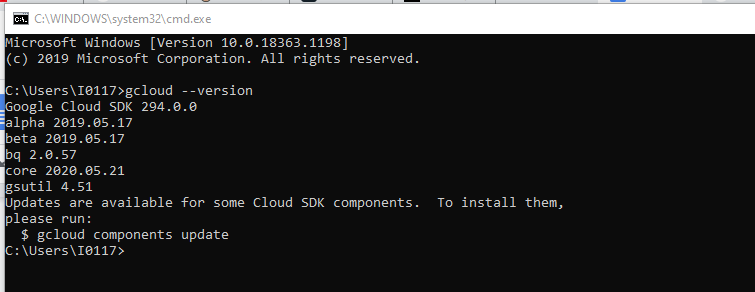
- If everything is OK, you can test it with the following command: gcloud --version
It should get something like this:
Then, you need to install Python:
- Download it from here: https://www.python.org/downloads/
- Then test it:
C:\Python64\python.exe --version
Then, it’s time to code the “last file API” in Python. We will need three files for this:
- app.py: the code of the Flask REST app
- Dockerfile: the Docker file for the image to be built
- sa.json: the Service Account file
- requirements.txt: the dependencies file
In order to start coding, you will some libraries first:
C:\Python64\python.exe -m pip flask gunicorn google-cloud-storage
The code for app.py is the following one:
import logging
from flask import Flask
from flask import request, jsonify, render_template
# from firebase_admin import credentials, firestore, initialize_app
from google.oauth2 import service_account
from google.cloud import storage
from bson.json_util import dumps
app = Flask(__name__)
storage_client = storage.Client.from_service_account_json('sa.json')
@app.route('/')
# API Version 1.0
def index():
"""Welcome to Last File API Version 1.0."""
button_text = "Get Last File"
return render_template('main.html', button_text=button_text)
@app.route("/last_file_m_individual/", methods=["GET"])
def list_m_individual_files():
"""List all files in GCP bucket."""
bucketName = request.args.get('bucketname')
bucketFolder = request.args.get('bucketfolder')
bucket = storage_client.get_bucket(bucketName)
files = bucket.list_blobs(prefix=bucketFolder)
fileList = [file.name for file in files if '.' in file.name]
last_file_pep = fileList[-1]
last_file_p = last_file_pep.split("/")
last_file = last_file_p[-1]
return last_file
@app.errorhandler(500)
def server_error(e):
logging.exception('An error occurred during a request.')
return 'An internal error occurred.', 500
if __name__ == "__main__":
app.run(debug=True,host='0.0.0.0',port=int(os.environ.get('PORT', 8080)))
Then the Dockerfile file:
# Use the official lightweight Python image.
# https://hub.docker.com/_/python
FROM python:3.8-slim
# Copy local code to the container image.
COPY . ./
RUN pip install -r requirements.txt
ENV PYTHONUNBUFFERED True
# Run the web service on container startup. Here we use the gunicorn
# webserver, with one worker process and 8 threads.
# For environments with multiple CPU cores, increase the number of workers
# to be equal to the cores available.
#CMD exec gunicorn --bind :$PORT --workers 1 --threads 8 --timeout 0 app:app
CMD gunicorn --bind :$PORT app:app
And lastly, the requirements.txt file:
Flask
gunicorn
pymongo
google-cloud-storage
Then, you will need a Service Account here (the sa.json file).
This Service Account must have the permissions to read the files in the bucket you will be querying from this API.
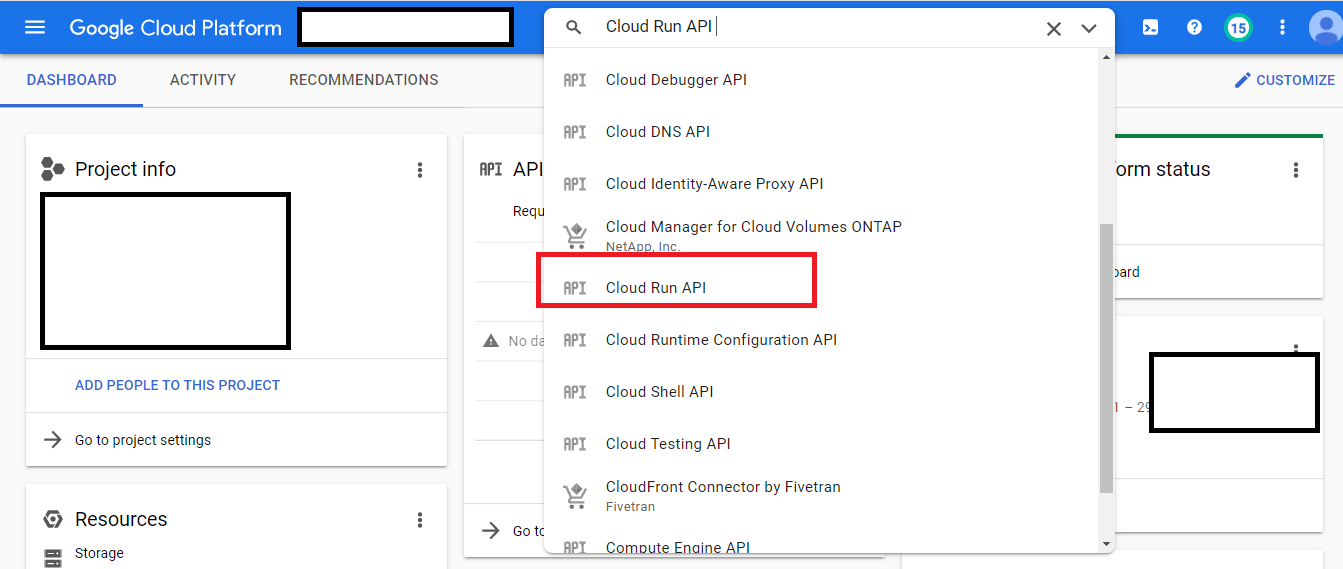
After this, you have to enable the Cloud Run API in the Google Cloud project you are using. In order to do that, you have to do the following:
- Visit: https://console.cloud.google.com/
- Then, you have to search the Cloud Run API
Then, it’s time for enabling the API:
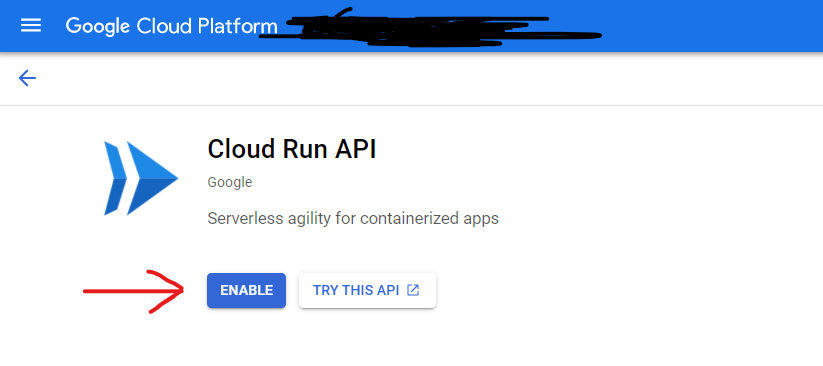
If everything is OK, then you need to deploy your API to Cloud Run.
To do that, we will use three commands:
gcloud config set project project-name
This will change to the Google Cloud project we are using for this.
Then, you need to build the Docker image with this command:
gcloud builds submit --tag gcr.io/project-name/service-name
This command will build the Docker image inside the Google Cloud infrastructure with all the requirements.
If everything is OK, it’s time to deploy the service:
gcloud run deploy service-name --image gcr.io/project-name/service-name --platform managed --region us-central1 --allow-unauthenticated
IMPORTANT: This command will deploy the application in an authenticated mode. This is recommended for development only. In order to deploy to production environments, it’s better to deploy with an authentication token; but this will be covered in another post.
If everything is OK, you can visit: https://console.cloud.google.com/run and see if your service is deployed there.
Cloud Run will generate a random domain name for your app using the following way: https://service-name-randomlettersnumbers-region-.a.run.app
Then, to test the API, you can use this code:
import requests
url = 'https://service-name-randomlettersnumbers-region-.a.run.app/last_file/'
bucketname = 'bucketnameaa'
bucketfolder = 'bucketfolderaa'
url_for = '{0}?bucketname={1}&bucketfolder={2}'.format(url, bucketname, bucketfolder)
r = requests.get(url_for)
result = r.text
print(result)
The API must return the last file in that bucket and in that particular folder of the bucket.
Now, let’s actually move the data from Google Cloud Storage to BigQuery
Part II: Move the daily data from Google Cloud Storage to BigQuery with Matillion
If you don’t know what is Matillion, here is a quick description:
Matillion ETL is an ETL/ELT tool built specifically for cloud database platforms including Amazon Redshift, Google BigQuery, Snowflake and Azure Synapse. It is a modern, browser-based UI, with powerful, push-down ETL/ELT functionality. With a fast setup, you are up and running in minutes
You can deploy Matillion on Google Cloud using the Google Cloud Marketplace:
In Matillion, there are two types of jobs: the orchestration job and the transformation job.
In this case, we will use an Orchestration job to move the data from Google Cloud Storage to BigQuery.
In order to do that, inside Matillion and create a new orchestration job. I will let an example here:
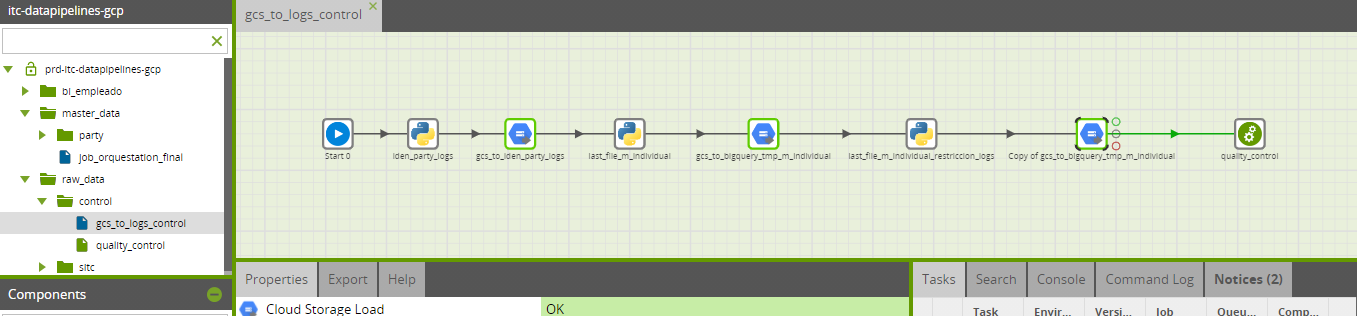
The main components here are two:
- Python script
- Google Cloud Storage Load
The Python script component will query the API we built in order to get the last file of a folder inside the designated bucket, and it will fulfill a variable inside the Matillion environment.
Then, that variable will be used as a parameter for the Cloud Storage Load component.
Here’s the example of the Python Script component:Then, inside the Cloud Storage Load component, you need to use the variable prm_last_file_iden_party to get the last file, and upload it to the table in BigQuery.
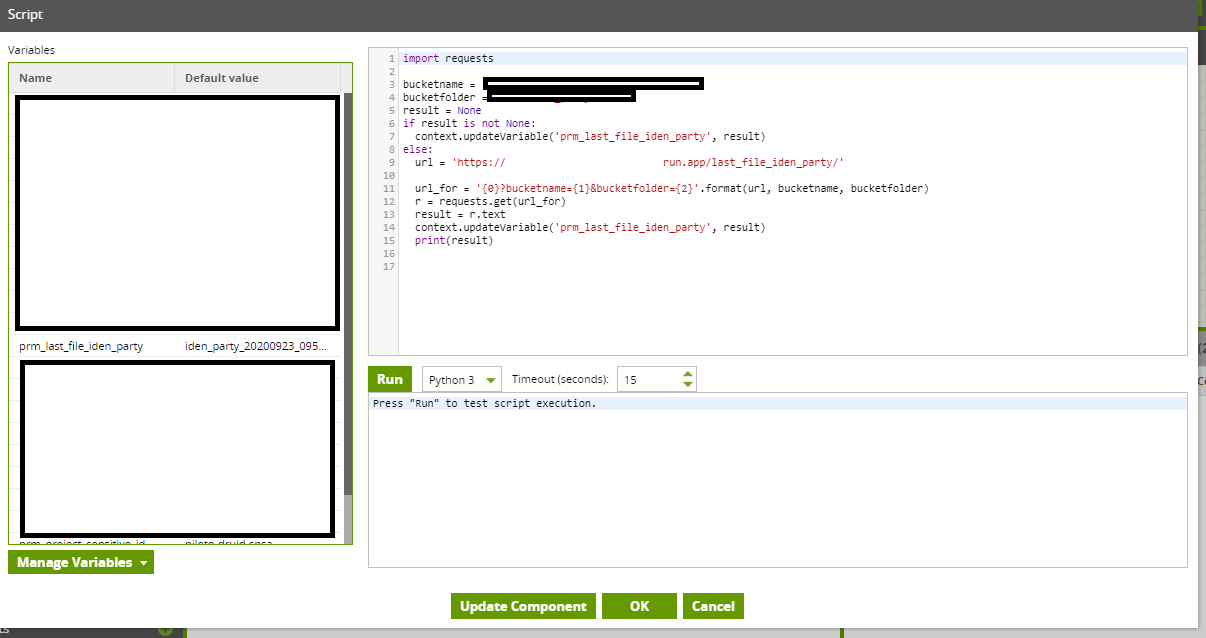
Then, inside the Cloud Storage Load component, you need to use the variable prm_last_file_iden_party to get the last file, and upload it to the table in BigQuery.
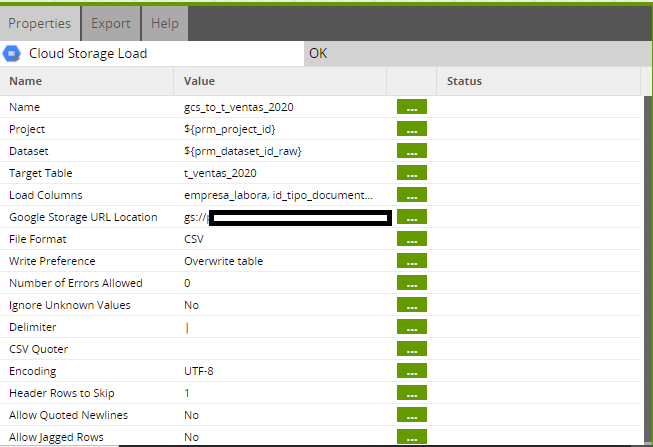
The key here is the Google Storage URL location. It must have the following format:
gs://bucketname/bucketfolder/$variablename
With this format, you will get the last file in the bucket folder, and upload it to the BigQuery table.
And voilá, in that way you can upload daily data from Google Cloud Storage to BigQuery using Matillion.
If you have any assistance with this, just send me an email and I will try to help you with it.
